Hadoop NamenodeとResourceManagerのHA構成についてメモしておきます。
簡単にHA構成が作りたいのであれば、CDHのCloudera Managerがおすすめです。
HA構成について 今回作るHA構成について簡単な説明。
Namenode HA
active / standby構成
Quorum Journal Manager (QJM)
Automatic failover
ResourceManager HA
active / standby構成
Automatic failover
RMは状態をZookeeperに書き出すのでJobの実行中にフェイルオーバーされてもJobは継続して実行される。
環境
CentOS 7.3
Java 8
Hadoop 2.7.3
Zookeeper 3.4.9
サーバの構成は次の通り。
HostName
IP
Service
master1
192.168.33.11
Namenode
master2
192.168.33.12
Namenode
slave1
192.168.33.21
Datanode
slave2
192.168.33.22
Datanode
slave3
192.168.33.23
Datanode
構築 淡々とHadoopの環境を構築していきます。
/etc/hostsの設定 全サーバで実行する。
hostnameの設定。
$ echo "192.168.33.11 master1" >> /etc/hosts $ echo "192.168.33.12 master2" >> /etc/hosts $ echo "192.168.33.21 slave1" >> /etc/hosts $ echo "192.168.33.22 slave2" >> /etc/hosts $ echo "192.168.33.23 slave3" >> /etc/hosts
Javaのインストール $ yum install -y wget java-1.8.0-openjdk
Hadoopのダウンロード $ wget http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz $ tar zxfv hadoop-2.7.3.tar.gz $ mv hadoop-2.7.3 /usr/local / $ sed -i -e 's|export JAVA_HOME=${JAVA_HOME}|export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk|g' /usr/local /hadoop-2.7.3/etc/hadoop/hadoop-env.sh $ mkdir -p /var/hadoop/dfs/{jn,nn,dn}
SSHの設定 Hadoopのスクリプトを使って各サーバのサービスを起動・停止するための設定をする。スクリプトからSSH接続するので鍵なしSSHの設定をする。
master1でssh鍵を生成して、master2はmaster1から公開鍵と秘密鍵をコピーする。
master1$ ssh-keygen master1$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys master1$ ssh master1
master1の~/.ssh/id_rsaと~/.ssh/id_rsa.pubをmaster2へコピー。
master2$ mkdir ~/.ssh master2$ echo "master1のid_rsaの中身" >> ~/.ssh/id_rsa master2$ echo "master1のid_rsa.pubの中身" >> ~/.ssh/id_rsa.pub master2$ chmod 600 ~/.ssh/id_rsa*
slaveにmasterの公開鍵を登録。$ mkdir ~/.ssh $ echo "master1のid_rsa.pubの中身" >> ~/.ssh/authorized_keys
MasterでSlaveの設定。
$ echo "slave1" > /usr/local /hadoop-2.7.3/etc/hadoop/slaves $ echo "slave2" >> /usr/local /hadoop-2.7.3/etc/hadoop/slaves $ echo "slave3" >> /usr/local /hadoop-2.7.3/etc/hadoop/slaves $ cat /usr/local /hadoop-2.7.3/etc/hadoop/slaves slave1 slave2 slave3
Zookeeperのインストール slave1, slave2, slave3にzookeeperをインストールする。
$ wget http://ftp.jaist.ac.jp/pub/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz $ tar zxfv zookeeper-3.4.9.tar.gz $ mv zookeeper-3.4.9 /usr/local /
アンサンブルの設定。$ cd /usr/local /zookeeper-3.4.9 $ cp conf/zoo_sample.cfg conf/zoo.cfg $ vi conf/zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/var/zookeeper clientPort=2181 server.1=slave1:2888:3888 server.2=slave2:2888:3888 server.3=slave3:2888:3888
myidを設定する。root$ mkdir /var/zookeeper && echo "N" > /var/zookeeper/myid
設定するmyidのNはzoo.cfgで設定したserver.Nと同じものをサーバ毎に設定する。
Zookeeperを起動する。
root$ bin/zkServer.sh start root$ bin/zkCli.sh -server 127.0.0.1:2181 [zk: 127.0.0.1:2181(CONNECTED) 0] ls / [zookeeper]
Hadoopの設定 設定ファイルはheader部分を除外。
まず、Hadoopの設定。
$ vi /usr/local /hadoop-2.7.3/etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> </configuration>
ここを参考 にyarnの設定。
それぞれのパラメータの詳細は上のドキュメントを参照。
$ vi /usr/local /hadoop-2.7.3/etc/hadoop/yarn-site.xml <?xml version="1.0" ?> <configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true </value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mycluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>master2:8088</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true </value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>slave1:2181,slave2:2181,slave3:2181</value> </property> </configuration>
次にココを参考 にHDFSの設定。
fencingの設定をしていないのでスプリットブレインが起きたときにメタデータが壊れる可能性があるので、必要があればsshfenceを設定すること。
それぞれのパラメータの詳細は上のドキュメントを参照。
$ vi /usr/local /hadoop-2.7.3/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>master2:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>master2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1:8485;slave2:8485;slave3:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true )</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/hadoop/dfs/jn</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true </value> </property> <property> <name>ha.zookeeper.quorum</name> <value>slave1:2181,slave2:2181,slave3:2181</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/hadoop/dfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/hadoop/dfs/dn</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
QuorumJournalManagerが偶数だと次の様なWarningが出るので、zookeeperと同様に奇数で構成する。17/02/23 05:46:30 WARN client.QuorumJournalManager: Quorum journal URI 'qjournal://master1:8485;master2:8485/mycluster' has an even number of Journal Nodes specified. This is not recommended!
起動 hdfsの起動から。
まず、Zookeeperを初期化する。master1$ hdfs zkfc -formatZK
エラーが表示されなければ問題なし。
journalnodeが起動していないとhdfsのformatできないのでスクリプトを使って起動する。yesと入力する必要がある。
master1$ sbin/start-dfs.sh Starting namenodes on [master1 master2] master2: starting namenode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-namenode-localhost.localdomain.out master1: starting namenode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-namenode-localhost.localdomain.out slave1: starting datanode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-datanode-localhost.localdomain.out slave2: starting datanode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-datanode-localhost.localdomain.out slave3: starting datanode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-datanode-localhost.localdomain.out Starting journal nodes [slave1 slave2 slave3] slave1: starting journalnode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-journalnode-localhost.localdomain.out slave2: starting journalnode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-journalnode-localhost.localdomain.out slave3: starting journalnode, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-journalnode-localhost.localdomain.out Starting ZK Failover Controllers on NN hosts [master1 master2] master2: starting zkfc, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-zkfc-localhost.localdomain.out master1: starting zkfc, logging to /usr/local /hadoop-2.7.3/logs/hadoop-root-zkfc-localhost.localdomain.out
HDFSを初期化。
master1$ hdfs namenode -format
これもエラーが無ければOK。
format後、Namenodeが落とされるので全プロセスを再起動する。master1$ sbin/stop-dfs.sh && sbin/start-dfs.sh
master2側はnamenodeの起動にコケているはずなのでStandbyとして起動する。master2$ ps axu | grep namenode master2$ hdfs namenode -bootstrapStandby master2$ sbin/hadoop-daemon.sh --config /usr/local /hadoop-2.7.3/etc/hadoop --script hdfs start namenode
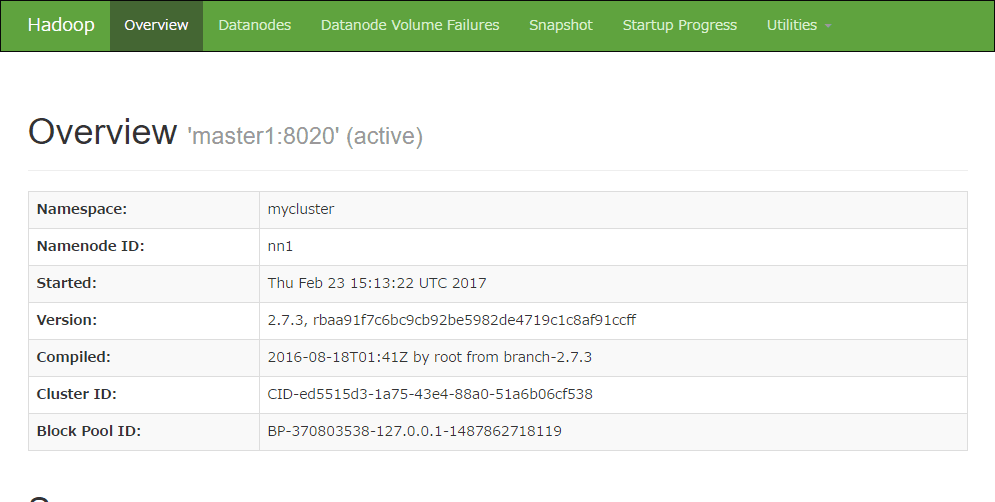
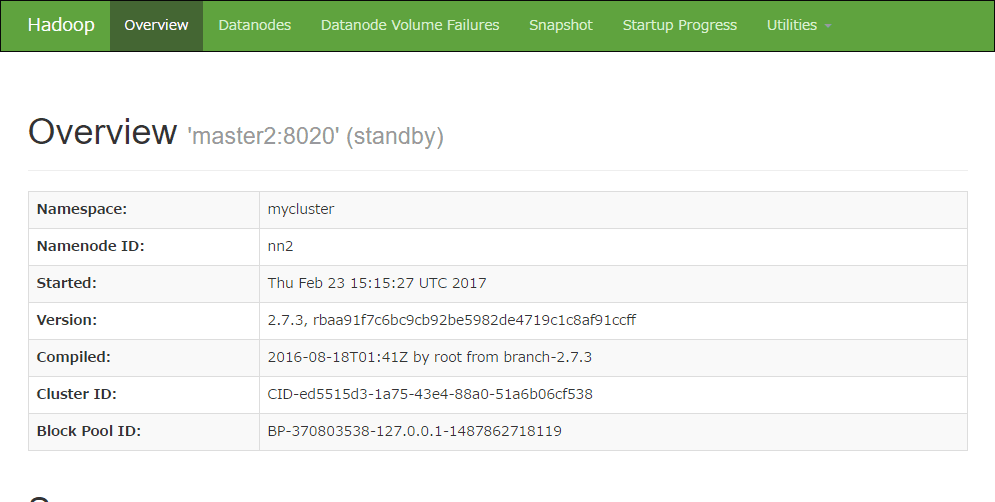
WebUIでステータスを確認することができる。うまく設定できている場合は、active/standbyが表示され確認することができる。
slave1, slave2, slave3が認識されていることを確認する。
$ hdfs dfsadmin -report Configured Capacity: 120636358656 (112.35 GB) Present Capacity: 114703486976 (106.83 GB) DFS Remaining: 114703474688 (106.83 GB) DFS Used: 12288 (12 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (3): Name: 192.168.33.22:50010 (slave2) Hostname: localhost Decommission Status : Normal Configured Capacity: 40212119552 (37.45 GB) DFS Used: 4096 (4 KB) Non DFS Used: 1977110528 (1.84 GB) DFS Remaining: 38235004928 (35.61 GB) DFS Used%: 0.00% DFS Remaining%: 95.08% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 23 15:22:06 UTC 2017 Name: 192.168.33.23:50010 (slave3) Hostname: localhost Decommission Status : Normal Configured Capacity: 40212119552 (37.45 GB) DFS Used: 4096 (4 KB) Non DFS Used: 1977110528 (1.84 GB) DFS Remaining: 38235004928 (35.61 GB) DFS Used%: 0.00% DFS Remaining%: 95.08% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 23 15:22:06 UTC 2017 Name: 192.168.33.21:50010 (slave1) Hostname: localhost Decommission Status : Normal Configured Capacity: 40212119552 (37.45 GB) DFS Used: 4096 (4 KB) Non DFS Used: 1978650624 (1.84 GB) DFS Remaining: 38233464832 (35.61 GB) DFS Used%: 0.00% DFS Remaining%: 95.08% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 23 15:22:06 UTC 2017
試しに、activeとなっているmaster1のnamenodeをkillしてみるとフェイルオーバーすることが確認できる。master1$ kill [namenode pid]
WebUIで確認するとmaster2がactiveになっていることが確認できる。
master1のプロセスを起動しておく。起動後は、standbyになっていることが確認できる。
master1$ sbin/hadoop-daemon.sh --config /usr/local /hadoop-2.7.3/etc/hadoop --script hdfs start namenode
次は、YARNを起動する。
master2$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local /hadoop-2.7.3/logs/yarn-root-resourcemanager-localhost.localdomain.out slave1: starting nodemanager, logging to /usr/local /hadoop-2.7.3/logs/yarn-root-nodemanager-localhost.localdomain.out slave2: starting nodemanager, logging to /usr/local /hadoop-2.7.3/logs/yarn-root-nodemanager-localhost.localdomain.out slave3: starting nodemanager, logging to /usr/local /hadoop-2.7.3/logs/yarn-root-nodemanager-localhost.localdomain.out
master1でも起動する。master1$ sbin/start-yarn.sh
yarnコマンドで状態を確認する。$ yarn rmadmin -getServiceState rm1 standby $ yarn rmadmin -getServiceState rm2 active
exampleで正しく動作するか確認する。
$ yarn jar /usr/local /hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 16 1000 (...) Job Finished in 2.712 seconds Estimated value of Pi is 3.14250000000000000000
clusterの状態は以下のURLで確認できる。
hdfsのときと同様のactiveのノードをkillしてみる。
$ ps axu | grep resourcemanager $ kill [resourcemanager pid] $ yarn rmadmin -getServiceState rm1 active
フェイルオーバーしていることが確認できる。
手動でフェイルオーバーさせることもできるがsplit-brainが起きる可能性があるっぽいので注意が必要。
$ yarn rmadmin -transitionToStandby --forcemanual rm1 $ yarn rmadmin -transitionToActive --forcemanual rm2 $ yarn rmadmin -getServiceState rm1 standby $ yarn rmadmin -getServiceState rm2 active
おわり。
参考
https://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html