Apache Kafka(以下、Kafka)の使用を検討した時に、公式ドキュメント をさらっと読んだのでまとめておく。
さらっと読んだ程度なので、間違っているところがあるかもしれませんのでご注意を。
主に、公式ドキュメント1~3章のまとめです。
対象のバージョンは0.9.0。
読む前にやっておくといいこと
まず、公式ドキュメントを読む前にイメージを掴むために以下を読んだ。
すごくわかりやすいです。
http://deeeet.com/writing/2015/09/01/apache-kafka/
http://www.slideshare.net/yanaoki/kafka-10346557
概要

Kafkaは大量のメッセージを高速に扱うことができる分散メッセージシステムで、メッセージングキューとして必要な様々な機能があります。
特徴は、速さ、拡張性、耐久性、分散処理。メッセージングキューを分散処理で管理する場合における複雑なことをたくさんやってくれるOSSです。
最大の特徴はメッセージが永続化されるところです。
Producer(書き込み)、Topic(Queue)、Consumer(読み込み)で構成されます。
ProducerがTopicに書き込み、ConsumerはTopicにデータをとりに行きます。データのやり取りはpublish subscribeモデルが採用されており、Consumer側で読み込むデータの流量を制御することができます。
可用性や分散管理面でzookeerの機能を多く使っており、zookeeperの起動が必要になっています。
Kafkaのイメージ
まず、一番簡単なイメージを書く。
Linux上にある一つのテキストファイルをイメージしてください。このファイルに書き込むプログラムがProducerで、このテキストファイルをtail -fで表示している複数のクライアントがConsumerです。
Consumerはテキストファイルを表示するだけなので特に意識することはないです。どこまでファイル読んだのかを管理するだけです。ファイルの”どこ”に当たるものはオフセットと呼ばれます。
ここでProducerが複数になった時のことを考えてほしいが、複数のProducerが同時に書き込んでくるような場合の同時書き込みの制御とか・・・考えるのはつらいですよね・・・。
といった時にKafkaを利用することでこういった問題を意識せずメッセージングキューが使えます。
Kafkaの仕組み
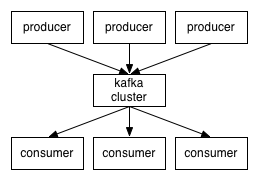
出処: http://kafka.apache.org/images/producer_consumer.png
基本的な仕組みはKafkaのイメージで書いた通り。
Topic
Topicのデータは複製されて管理されます。zookeeperの機能がてんこ盛りで使われていると思われる。パーティションにわけられたFIFOのQueueで継続的にコミットログに追加されたメッセージを順序付きで管理されます。各ログはオフセットと呼ばれる不変で一意なシーケンシャルIDが付与されてメッセージを認識しています。
大量のデータを保存することは問題にならないし、ログの保存期間を設定して自動的に削除することができます。
Producer
Topicへ書き込むProducerはKafkaでメッセージを受け取るBrockerのlistを持っておく必要があります。どのBrockerに書き込んでもKafkaで管理されるzookeeperで選出されたリーダーのBrockerにメッセージが送られてTopicに書き込まれます。
Consumer
ConsumerでTopicからデータを読みだす場合はzookeeperに接続してリーダーとなっているBrockerに接続します。現時点で処理の詳細がわからないが、接続先が死んでいる可能性があるのでzookeeperの接続先リストももっておかなければならないはず。
基本的にTopicはレプリケートされて複数あるが最新のデータをリーダーから読みだす。
機能面
さらっと書く。詳細は4章以降を読み込むと理解できる。
可用性
Zookeeperの機能を使って可用性を確保する仕組みがある。レプリカの変更管理、Brockerのリーダー選出などなど。Zookeeperを使っているのでディスクIOとか気をつけないといけないと思われる。
負荷分散
クラスタ内の負荷のバランスが保てるような仕組みがある。
Producerから書き込まれるデータを扱うTopicのパーティションの管理の方法のようです。
順序保証
TopicとパーティションとConsumerの割当方次第でメッセージの順序に完全な順序が保てる。
保証
- 特定のトピックパーティションにプロデューサによって送信されたメッセージは、それらが送信された順序で追加されます。例えば、メッセージM1、M2の順で同じプロデューサが送信された場合、M1はM2よりも低いオフセットでログの前に表示される。
- Consumerはログに保存されている順序でメッセージが表示されます。
- 複製がN個でトピックが構成されている時、コミットされたメッセージを失うことなくN-1台のサーバーの障害まで耐えられる。
ローリングアップデート
0.8あたりから無停止でアップデートできる。
API関連
Producer API
Producer APIとして以下が用意されている。<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0</version>
</dependency>
Concumer API
Concumer APIはいくつか用意されているがNew Consumer APIを使いましょう。
Old High Level Consumer API, Old Simple Consumer APIもあるが名前の通り。
New Consumer APIは以下の通り。<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0</version>
</dependency>
設定
Brocker設定、Producer設定、Consumer設定の全項目がマニュアルにすべて書いてあるので本番環境で使う場合はしっかりチューニングすること。
まとめ
Kakfaを理解するためにはZookeeperの理解も必要そうです。ページキャッシュの仕組みをうまく使って設計されているみたいです。さくっと動かした感触ではかなり使えそうな感触。次は、Producer APIをVert.xから叩くみたいな使い方をやっていこうと思います。